网络协议:HTTP2详解

HTTP/1.x 简介
要想深刻的了解 HTTP/2,那么我们必须对 HTTP/1.x 本身以及它的缺点有一定程度的熟悉,而这一节,我们对 HTTP/1.x 的请求
形式以及其缺点进行一个简单的回顾.首先,HTTP/1.x 的一个非常明显的特征是它是明文协议,也就是说,所有的内容,人类可以阅读,
例如这是一个简单的请求的样子:
GET / HTTP/1.1
Host: jiajunhuang.com
这个请求表明,此HTTP请求,请求获取 jiajunhuang.com 这个网站的 / 的内容,请求方法是 GET,使用的协议是 HTTP/1.1.
而这个网站很可能会返回如下响应:
HTTP/1.1 101 Switching Protocols
Connection: Upgrade
Upgrade: h2c
响应中,首先表明响应是使用 HTTP/1.1,状态码是 101,状态码的含义是 Switching Protocols,接下来就是 HTTP/1.1 中
的头部,此响应包含两个头部: Connection, Upgrade.
通过上面的讲解,我们了解到了一些专有名词,为了方便理解后续的内容,我们需要在此作出解释:
- 明文协议:与明文协议对应的名词是二进制协议,这么来简单的理解一下,我们知道ASCII编码是把8个bit读取位一个byte,而这个
byte的类型是char,例如
a对应的二进制是0110 0001,给一串有意义的明文协议的二进制流,我们可以按照8个bit一组,翻译成 可以显示的英文字符.但是二进制协议则不可以,因为尽管我们也可以按照8个bit一组去读取并且显示,但是结果是,我们得到的是 一些看不懂的乱码,例如各种奇奇怪怪的符号.当然,这只是举个例子,实际上二进制流可能不是ASCII编码,可能是UTF-8,那就需要 另外的规则去解析了. - 客户端:例如使用浏览器浏览网页的例子里,浏览器就是客户端.
- 服务器:例如使用浏览器浏览网页的例子里,生成网页内容的那一方就是服务器.
- 请求:例如使用浏览器浏览网页的例子里,浏览器需要告诉服务器自己想要看什么内容,这个步骤就叫请求.
- 响应:例如使用浏览器浏览网页的例子里,服务器返回给浏览器的网页就是响应.
- 头部:HTTP/1.x 中,请求或者响应分为两个部分,一部分是头部,一部分是payload.头部是最开始的用冒号分隔的那些键值对,例如
Connection: Upgrade和Upgrade: h2c就是头部. - 状态码:HTTP/1.x 中规定了一系列数字,我们称之为状态码,例如,200代表成功,400代表客户端所给的请求有问题.
回顾 HTTP/1.x 的请求流程
如果我们使用浏览器打开一个网站,那么流程通常是这样的,浏览器发送请求:
GET / HTTP/1.1
Host: jxufe.cn
而响应则是 http://jxufe.cn/ 首页的内容,是一个网页,其中包含许多图片和CSS以及JS等静态资源,为了展示出最终的结果,浏览器
还需要把这些资源下载到本地并且进行渲染.而由于我们的浏览器并没有开启 HTTP/1.0 及以上支持的 Keep-Alive,所以对于每一个
资源,浏览器都要新建一个TCP连接去下载资源.例如下图是访问 http://jxufe.cn 的网络请求示意图:

从图中我们可以看出来,有大批的资源要下载,而浏览器通常不能新建大量TCP连接,通常的实现是同一个网站开启6个连接.所以如果每个
资源整个流程需要1秒钟,那么下载32个资源,就要32秒钟,这对于用户来说,体验是极差的.即便开启了 Keep-Alive ,由于
Head-of-line Blocking 的问题,也无法充分利用底层的TCP连接.
此外,如果我们点开每一个请求细看,我们可以发现,头部中有大量的重复内容,例如:
Host: jxufe.cn
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36
等等.当请求量一大,这些重复的头部其实浪费了很多资源.
而 HTTP/2 就是为了解决上述问题而设计的.
HTTP/2 简介
首先我们点开这个网站来看看 HTTP/2 和 HTTP/1.1 在性能,或者说用户体验上的区别:https://imagekit.io/demo/http2-vs-http1 .
可以看出来,HTTP/2 的加载速度会比 HTTP/1.x 快很多,尤其是当您所处的网络环境比较差的时候,差别尤其明显.那么 HTTP/2 是
怎么做到的呢?接下来我们会讲到 HTTP/2 的一些特性,等您了解完之后,就可以知道为什么 HTTP/2 在性能上会有如此大的提升了.
不过在此之前,我们需要先讲一些前置知识.
-
扩展:字节序 进行系统编程或者网络编程,一定要了解的一个概念是字节序,什么叫字节序呢?就是字节的顺序.在计算机中,有大端和小端两种分类, 其定义是,从左往右读一系列字节的时候,如果决定性更大的那一部分在左边,决定性更小的那一部分在右边,那么这就是大端,反之则 是小端.我们拿一个十进制的数字来举例子,1234567,1的决定性更大,为什么呢?如果1变成了2,那么整个数字的数值将会加大许多, 而如果是7变成了9,则对整个数字的改变不会有太大(才2而已).人类习惯的表示法都是大端,网络序也通常是大端(没有明文规定,但是IP 协议中是如此约定,现实实现中也是如此).
-
所有数值都是网络序
HTTP/2中规定,所有的数值都是网络序.
二进制分帧
HTTP/2 中有一个明显的特征就是,不再采用明文协议,转而使用二进制协议,HTTP/2 中引入了一个新的概念,叫做帧,原本在 HTTP/1.x
中,一个请求中包含头部和payload,头部和payload 的划分规则是 \r\n\r\n,而 HTTP/2 中,把头部和payload分开,放入到两种不同的
帧里.
-
为什么使用二进制协议? 二进制协议在解析的时候更加高效.所谓高效,我们必须和
HTTP/1.x对比一下才知道,在HTTP/1.x中,对于如下请求:GET / HTTP/1.1 Host: jiajunhuang.com我们的解析顺序是,一个字节一个字节读取,首先读到第一个空格为止,然后判断所读到的字节长度以及内容,是
GET,POST等等HTTP/1.x中规定的哪一种方法,然后继续读取到下一个空格,我们得到/,意思是请求的内容是/这个位置的内容,继续读取 得到HTTP/1.1\r\n,这里是说明使用的是HTTP/1.1版本的协议,接下来的内容是头部.总而言之,HTTP/1.x的解析流程就是这样的.而在接下来的内容中,我们可以看到,
HTTP/2中,解析的流程是,读取TCP流中的前面9个字节,根据第4个字节的数值,判断出这个 帧的类型,然后根据前面3个字节得出这个帧的payload有多长,继续在流中读取内容,并且进行解析和处理. -
为何分帧 对于这个问题,我们可以联想一下TCP为何要把数据分成一小块一小块进行传输呢?试想,如果我们的请求中包含的是一个1G的文件的 内容,而我们一次性把文件写入流中,由于要保证解析的时候的简便性,我们约定,一次只写入一个完整的请求的内容,如同
HTTP/1.x中所做的那样,那么在写完这整个 1G 的文件内容之前,我们都不能写入其他内容.这种时候就体现出分帧的作用了, 如果我们把 请求的数据分块n个块,每次写入1M呢?那么在这个时候,就可以插入其他请求或者响应的内容了.但是这个时候我们要怎么区分哪个 内容是哪个请求的呢?这就需要提到 stream(流) 这个概念了,我们在此暂时按下不表. -
帧的类型及其格式 直接从RFC中把对于帧的格式抄过来看一下:
+-----------------------------------------------+ | Length (24) | +---------------+---------------+---------------+ | Type (8) | Flags (8) | +-+-------------+---------------+-------------------------------+ |R| Stream Identifier (31) | +=+=============================================================+ | Frame Payload (0...) ... +---------------------------------------------------------------+上面我们说到解析的时候,我们先读取9个字节,为什么是9个字节呢?从上面帧的格式我们可以看出来,因为24+8+8+1+31 = 72, 而8个bit为一个byte(字节),所以是9个字节,也就是72bit.我们需要解释一下帧的格式定义中,各个块的意义.
- Length: 这里说明了帧的头的后边,
Frame Payload的长度,它是一个24bit长的unsigned int,单位是byte.因此,通常 情况下,payload最多能传输2^14 (16,384)个byte,那如果想要传输更长怎么办呢?可以通过SETTINGS帧,传输一个叫做SETTINGS_MAX_FRAME_SIZE的设置来改变. - Type: 这8个bit表示帧的类型,例如
0000 0000表示这个帧是DATA,而0000 0001表示这个帧是HEADERS等等. - Flags: 这8个bit是留给各个类型的帧使用的,每个帧可以设置一些标志位来表示一些特殊的意义,例如
HEADERS帧中,可以设置 一个叫做END_HEADERS的位来表示这个帧里就已经传输了所有需要的头部内容,如果没有这个标志的话,我们还需要继续读取内容 以便获取完整的头部. - R: 这个位是空着的,没有使用.
- Stream Identifier: 这是我们上面提到的stream,也就是流的ID,就是一个编号,stream我们会在下一节进行介绍.
- Frame Payload: 这就是这个帧实际需要携带的数据,注意上面所说的 Length,指的就是payload的长度,并不包括我们所说的帧的头的长度.
- Length: 这里说明了帧的头的后边,
-
Go代码解析示例 我们简单来看一下Go语言中,是怎么读取一个帧的:
func readFrameHeader(buf []byte, r io.Reader) (FrameHeader, error) { _, err := io.ReadFull(r, buf[:frameHeaderLen]) if err != nil { return FrameHeader{}, err } return FrameHeader{ Length: (uint32(buf[0])<<16 | uint32(buf[1])<<8 | uint32(buf[2])), Type: FrameType(buf[3]), Flags: Flags(buf[4]), StreamID: binary.BigEndian.Uint32(buf[5:]) & (1<<31 - 1), valid: true, }, nil }可以看出来,我们读取frameHeaderLen,也就是9个字节到buf,然后把前三个字节的内容读取出来,设置为uint32类型的数值来保存, (因为没有uint24),然后第4个字节和第五个字节分别保存为Type和Flags,其余字节按照大端序读出来,作为StreamID,读取完帧 的头之后,我们就可以根据Length的数值来读取payload了,类似于:
buf := make([]byte, Length) io.ReadFull(r, buf)
流
-
为什么要有流 前面提到了
HTTP/2把数据分成了帧,而HTTP/2还有一个重大特性就是多路复用,这是怎么做到的呢?如果我们可以想办法 让客户端和服务器之间同时传输多个请求或者响应的话,就达到了我们的目的,但是我们要想个办法区分哪些帧串起来可以组成一个 请求或者一个响应.有一个办法,就是抽象出一个概念,我们给这个概念一个唯一的ID,因为TCP会保证顺序,也就是说,我们是以 何种顺序写入帧,在读取帧的时候就是何种顺序,所以,我们读取数据的时候,把相同ID的帧拼在一起,就可以组成一个请求或者 响应.而我们所说的这个抽象概念,就是stream(流). -
流的ID 我们已经知道了,通过流,我们可以做到多路复用.但是
HTTP/2中还有一个特性,叫做server push,就是说,在建立连接之后, 服务器可以主动向客户端发送数据,那么问题来了,既然每个请求或者响应都要有一个ID,而服务器和客户端都可以同时向对方发送 数据,每个帧里都会包含一个流的ID,他们必须是唯一的,如何保证服务器和客户端生成的ID不会冲突呢?本地生成一个,然后发给 对方让对方确认对方没有占用然后再使用该ID?这样显然太低效了,我们需要一个更好的方案.这让我想起了一个面试题,分布式 环境中,怎么设计一个发号器(这个发号器产生的ID必须保证全局唯一)?方案一是,采用一个集中发号器,例如一个Redis或者 MySQL中设置一个自增列,但是显然这种方案不适用于HTTP/2的情形;方案二是,每个子系统各自有一个发号器,例如1,2,3, 每次产生一个号码之后,增加3.当全部产生完一轮号码之后,三个子系统的号码就变成了4,5,6,然后再进行下一轮.这种方案 很适合HTTP/2,恰巧,它就是这样做的.协议规定,客户端使用奇数的ID,服务器使用偶数的ID,ID不可以重复使用,每次发起新的 请求的时候,都会使用一个更大的ID. -
状态机以及状态转换 流的状态机我们直接从RFC截图过来:
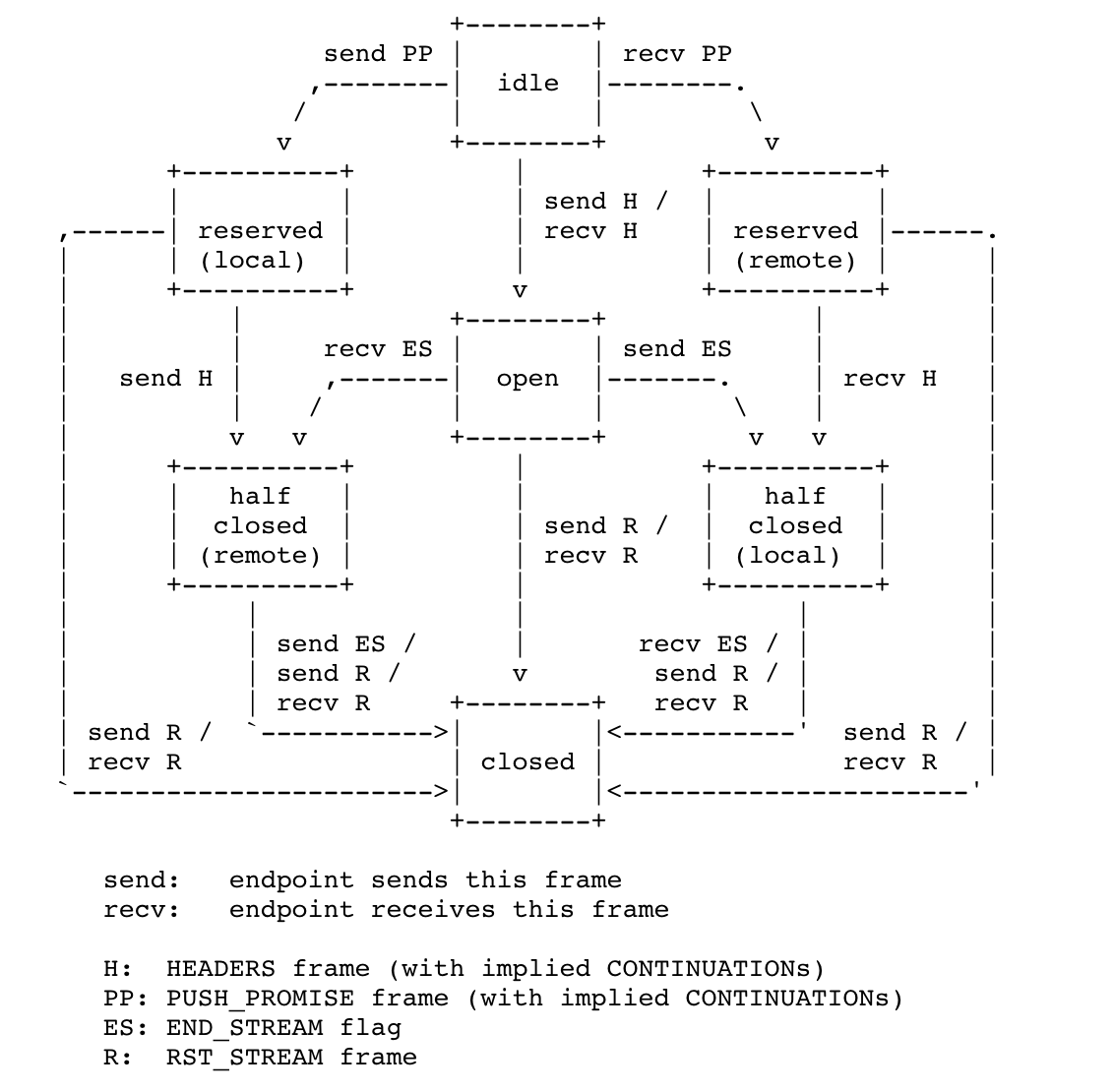
我们先来看一下这张图里,流的7种状态:
- idle:流目前尚未启用
- open:流目前正在使用
- closed:流已经使用完成
- reserved(local):本地保留,即将要使用但是尚未使用
- reserved(remote):远端保留,即将要使用但是未使用
- half closed(local):本地半关闭,即将关闭但是尚未关闭
- half closed(remote):远端半关闭,即将关闭但是尚未关闭
然后看一下里边的缩写:
- H:HEADERS这种帧
- PP:PUSH_PROMISE这种帧
- ES:帧设置了END_STREAM这个flag
- R:RST_STREAM这种帧
我们熟悉了这些之后,就可以很容易的读懂这个状态转换图了,例如:
- 收到或者发送HEADERS这种类型的帧会使流进入open状态,也就是说,HEADERS一定会建立一个新的流
- 发送PUSH_PROMISE的那一方会把流保存为reserved(本地)的状态,当发送完HEADERS之后会变成half closed(remote)状态
当然了,这个状态转换图要结合RFC中各个细节描述一起来理解会更好.
-
流的优先级
HTTP/2中,流是可以设置优先级的,怎么设置哪个流优先呢?简单,声明这个流依赖于哪个流即可,这样,优先传输其依赖的流, 再传输其本身,就可以体现出优先级了,在 HEADERS 帧的payload里设置 它所在的流所依赖的流的ID即可.这是用来开启一个新的流的时候声明依赖,那怎么在流处于打开状态之后改变依赖顺序呢?发送 类型为 PRIORITY 的帧即可.除了可以设置流的依赖,还可以设置权重.没有声明依赖的流有一个默认的依赖的流,ID是0.举个例子,下边,A没有声明依赖,B和C都依赖A,A的依赖默认是0,也就是不存在的 一个流.
当收到一个新的依赖的时候,它会被插入到原有的依赖树里,所有的子树不区分先后顺序,例如现在收到一个新的流D,它依赖于A, 则会发生下图的变化,当然,BDC的顺序不一定是BDC,也可能是BCD等等.
A A / \ ==> /|\ B C B D C此外,可以设置一个exclusive的flag,设置了这个flag之后,插入依赖树的时候,会把所依赖的父节点的原有子节点下放,成为 自身的字节点,而原来的父节点成为自身的父节点,也就是说,自己独占原来的父节点.例如上面的情况,如果收到新的流D,它 依赖于A,而且同时设置了exclusive的flag,就会发生下图的变化:
A A | / \ ==> D B C / \ B C -
流的权重 我们还没有看过HEADERS里如果声明流的依赖,二进制的内容会是什么格式呢:
+---------------+ |Pad Length? (8)| +-+-------------+-----------------------------------------------+ |E| Stream Dependency? (31) | +-+-------------+-----------------------------------------------+ | Weight? (8) | +-+-------------+-----------------------------------------------+ | Header Block Fragment (*) ... +---------------------------------------------------------------+ | Padding (*) ... +---------------------------------------------------------------+我们可以发现,Stream Dependency下边跟了个weight,接下来我们来看看上边说的weight有什么用.上边说了,同一个节点下的 流是没有先后顺序的,但是,同一个节点下的字节点,是有权重的,而这个权重,就是weight所声明的权重.举个例子,如果是 这样的依赖:
A / \ B C其中B的权重是4,C的权重是8,那么当处理完A之后,B和C的资源分配比例是1:2.
-
flow control 流程控制是指,
HTTP/2中,对流和其下方的TCP连接进行管理.进行管理的方式是发送类型为WINDOW_UPDATE的帧. 流程控制是逐跳的,也就是说,如果有A-B-C三个参与方,流程控制只能是A-B,B-C之间各自有控制,B不能把A发送的WINDOW_UPDATE帧转发到C.WINDOW_UPDATE帧可以是针对流也可以是针对连接的,如果帧的头部里,StreamID是0,则是针对 连接的,否则,则是针对具体的流的.那么流程控制里设置的Window Size设置的是啥呢?Flow control only applies to frames that are identified as being subject to flow control. Of the frame types defined in this document, this includes only DATA frames.
如上,
WINDOW_UPDATE只能设置DATA这种帧的payload的大小. -
错误处理
HTTP/2中有两种类型的错误,一种是针对流的错误,一种是针对连接的错误.针对流的错误终止那个流的使用,针对连接的错误 终止整个TCP连接.
头部压缩
TODO(还没细读 rfc7541)
- 扩展:哈夫曼编码
约定的错误
参考:https://tools.ietf.org/html/rfc7540#section-7
SETTINGS 中可以设置的内容
参考:https://tools.ietf.org/html/rfc7540#section-6.5.2
如何与 HTTP/1.x 兼容
参考:https://tools.ietf.org/html/rfc7540#section-3
首先,HTTP/2 共用 http:// 和 https:// 这两个scheme,也就是说,服务器和客户端要想办法从 HTTP/1.x 的连接升级到
HTTP/2 的连接,大概的流程如下:
客户端发送如下请求:
GET / HTTP/1.1
Host: server.example.com
Connection: Upgrade, HTTP2-Settings
Upgrade: h2c
HTTP2-Settings: <base64url encoding of HTTP/2 SETTINGS payload>
如果服务器不支持 HTTP/2,则如同往常一样返回,但是不会出现Upgrade这个头部,例如:
HTTP/1.1 200 OK
Content-Length: 243
Content-Type: text/html
...
而如果服务器支持 HTTP/2,则返回101,带上Upgrade这个头部并且随即开始的内容就是 HTTP/2 的内容:
HTTP/1.1 101 Switching Protocols
Connection: Upgrade
Upgrade: h2c
[ HTTP/2 connection ...
但是注意,上面所说的开始 HTTP/2 的内容,是这样的:客户端立即发送 Preface,服务器收到后,也发送Preface,然后就开始
各自发送不同的帧.Preface的内容是固定的:PRI * HTTP/2.0\r\n\r\nSM\r\n\r\n,其中客户端无需等待收到服务器发送的Preface,
也就是说,客户端发送完Preface之后,就可以正常开始发送各种帧了.
参考
- https://tools.ietf.org/html/rfc7540
- https://tools.ietf.org/html/rfc7541
- https://developers.google.com/web/fundamentals/performance/http2/
- https://http2.github.io/faq/