Go进阶29:高效io.Reader/io.Writer S3数据传输

这里有一个需求就是把云储存(AWS S3)的很多小文件压缩成一个大的压缩文件. 我们脑海第一个想到的办法就是下载全部的小文件,使用压缩软件创建压缩包,在上传到S3中, 当然这个方案时可行的,但是我们这里有一个更好的方法使用Go语言的标准库io.reader/io.writer.
1. “直觉”的方案
首先定义 S3的文件管理上传下载结构
var (
downloader *s3manager.Downloader
uploader *s3manager.Uploader
)
从S3下载小文件保存到小文件,创建zip压缩包,写入小文件的内容到压缩包,上传zip压缩文件的内容到S3.
func zipS3Files(in []*s3.GetObjectInput, result *s3manager.UploadInput) error {
filesToZip := make([]string, 0, len(in))
// 下载小文件到本地磁盘
for _, file := range in {
pathToFile := os.TempDir() + "/" + path.Base(*file.Key)
f, _:= os.Create(pathToFile)
downloader.Download(f, file)
f.Close()
filesToZip = append(filesToZip, pathToFile)
}
// 创建零时zip压缩文件
zipFile := os.TempDir() + "/" + path.Base(*result.Key)
f, _:= os.Create(zipFile)
defer f.Close()
zipWriter := zip.NewWriter(f)
for _, file := range filesToZip {
// 在zip 压缩包创建文件
w, _:= zipWriter.Create(file)
// 打开下载好的本地小文件
inFile, _:= os.Open(file)
// 拷贝小文件的内容到压缩包
io.Copy(w, inFile)
inFile.Close()
}
zipWriter.Close()
// seek 移动读写游标
f.Seek(0, 0)
// 上传zip文件内容
result.Body = f
_, err = uploader.Upload(result)
return err
}
这个方法看起来时非常简单明了,但是我们可以改进它,我们没有必要把小文件和zip压缩包文件写到磁盘上. 如果我们想在AWS Lambda 中运行代码,但是它的存储/temp空间限制512MB. 我们不适用硬盘.我们将使用内存,AWS Lambda中最大内存使用数量高大3GB.
2. Stream流解决方案
我们可以创建一个管道Pipe,它将数据从S3 Bucket 经过 zip.Writer 压缩在送回S3 bucket里面. 这个过程不涉及硬盘.使用简单易用的接口io.Reader和io.Writer就可以实现以上的功能.流程图如下:
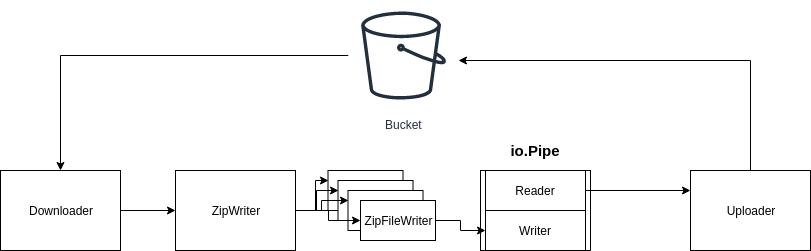
首先我们创建一个管道Pipe来传送小文件到 zip.Writer 在到S3 bucket uploader, pr 代表pipe reader, pw 代表 pipe writer.
pr, pw := io.Pipe()
然后使用pipe writer作为参数pr 创建 zip.Writer.
zipWriter := zip.NewWriter(pw)
任何内容写入都通过pip writer pw 传输.
现在我们遍历每个文件并在其中创建一个 writer zip.Writer
for _, file := range in {
w, _ := zipWriter.Create(path.Base(*file.Key))
现在我们来看一下S3下载签名文档:
func (d Downloader) Download(w io.WriterAt, input *s3.GetObjectInput, options ...func(*Downloader)) (n int64, err error)
Download方法需要io.WriterAt,os.File满足此接口,但zipWriter.Create返回io.Writer. AWS SDK 使用io.WriterAt用于并发下载.我们可以通过以下设置禁用此并发下载功能.
downloader.Concurrency = 1
我们创建自己的struct,该struct将提供该方法 WriteAt,使其满足接口要求io.WriterAt.它将忽略offset,
因此其工作方式类似于io.Writer.
io.WriterAt由于并发下载,AWS SDK之所以使用,是因为它可以在偏移位置写入(例如,在文件中间).
通过禁用文件并发下载,我们可以安全地忽略offset参数,因为它将按顺序下载的.参考stackoverflow Buffer implementing io.WriterAt in go
type FakeWriterAt struct {
w io.Writer
}
func (fw FakeWriterAt) WriteAt(p []byte, offset int64) (n int, err error) {
// ignore 'offset' because we forced sequential downloads
return fw.w.Write(p)
}
现在我们可以通过将writer包装到我们的FakeWriterAt结构体中来下载文件.
downloader.Download(FakeWriterAt{w}, file)
下载每个文件之后,我们需要调用closer.
zipWriter.Close()
pw.Close()
这样,我们将文件下载到zipWriter中的writer,先对其进行处理,然后再将其写入pipe writer中.
现在我们需要将ZIP上传回S3 Bucket中.我们正在给管道写入数据,不从中读取数据.我们将UploadInput的body设置为pipe reader.
result.Body = pr
uploader.Upload(result)
最后一步是并行运行下载和上传,当下载完成处理了一些数据块之后,可以立即将其上传到S3 bucket. 我们使用并行执行这两个步骤,go func()..并将其与wait group同步.
这是最终代码:
type FakeWriterAt struct {
w io.Writer
}
func (fw FakeWriterAt) WriteAt(p []byte, offset int64) (n int, err error) {
// ignore 'offset' because we forced sequential downloads
return fw.w.Write(p)
}
func zipS3Files(in []*s3.GetObjectInput, result *s3manager.UploadInput) error {
//设置单线程下载
downloader.Concurrency = 1
// 通过io.Pipe创建管道
pr, pw := io.Pipe()
// 使用pipe writer 参数创建 zip.writer
zipWriter := zip.NewWriter(pw)
wg := sync.WaitGroup{}
// 等待s3 的下载器 和上传器执行完成
wg.Add(2)
// Run 'downloader'
go func() {
// 必须要使用closer 关闭zip.Writer 和 pipe wirite
// zip.Writer closer不会自动的关闭
defer func() {
wg.Done()
zipWriter.Close()
pw.Close()
}()
for _, file := range in {
// 文件内容下载到 zip.Writer的Writer
w, err := zipWriter.Create(path.Base(*file.Key))
if err != nil {
fmt.Println(err)
}
_, err = downloader.Download(FakeWriterAt{w}, file)
if err != nil {
fmt.Println(err)
}
}
}()
go func() {
defer wg.Done()
// 上传压缩文件
// result.Body 从pipe reader 取回内容
result.Body = pr
_, err := uploader.Upload(result)
if err != nil {
fmt.Println(err)
}
}()
wg.Wait()
return nil
}
正如您所见,这里没有做异常处理,error handle 不在本文讨论范围之内.
还有如果downloader.Download失败,我也希望上传失败. 当您要使用时,这是一个很好的用例context.我们可以创建上下文,例如time out.
ctx, cancel := context.WithTimeout(context.Background(), time.Minute * 4)
如果下载失败,我们执行 ctx.cancel(),然后取消上传.
3. 结论
关于时间性能,我尝试处理20MB小文件压缩到5MB的zip文件. 而通过第一个简单的解决方案花费了7s.
使用这个方法花费了5s, 但是不涉及磁盘读写,因此您可以将其用于AWS Lambda,但仍然AWS Lambda只有5分钟执行时间. 最后,我想说的时Go语言标准库时非常强大的.监视简单的interface设计.